Overview Data Preparation Topic Modeling Sentiment Analysis Outcome and Reflection
Foreword
This project began as a cooperative study project between students at the University of Osnabrück and deepsight GmbH. The goals of the project were to implement a natural language processing pipeline optimized to the analysis of short, open comments such as those found in employee survey data. It is common to include open-response questions within employee surveys as these questions provide additional incentive for employees to express their satisfaction relevant to topics of concern which may not be known to the surveying department. However, these questions pose an additional challenge to analysis given that the responses are necessarily unstructured. In this project, we develop an end-to-end solution for the analysis of short texts via document clustering and sentiment analysis of clustered documents.
Approach
To provide focused reporting on employee satisfaction relevant to topics of recurrent interest, we employ a document clustering approach to identify topics of interest, and then analyse the sentiment distribution within each topic via sentiment classification. Document clustering is a common NLP task for information retrieval and text classification, and as such there exist a variety of available algorithms and tuning methods for achieving interpretable clusters of documents. [1] Further information on our document clustering approach can be found in the Topic Modeling section of this report.Sentiment classification is a common NLP task which poses sufficient difficulty given our domain and the brevity of comments for which we aim to identify sentiment. Given these challenges, approaches such as keyword identification do not produce consistently satisfactory results. In the end, our approach to sentiment classification involves a custom-trained recursive neural network model trained on twitter data. Further information on our sentiment classification approach can be found in the Sentiment Analysis section of this report.
Our document clustering and sentiment analysis methods depend on the features extracted from pretrained word embeddings, which are sensitive to spelling errors and unnecessary characters. Because of this, we employ several preprocessing stages to render the original data, while also filtering for undesired tokens such as stop words and highly-frequent words. Further information on the preprocessing methods we employ can be found in the Data Preparation section of this report.
The end-to-end open-comment analysis pipeline are summarized by the following diagram.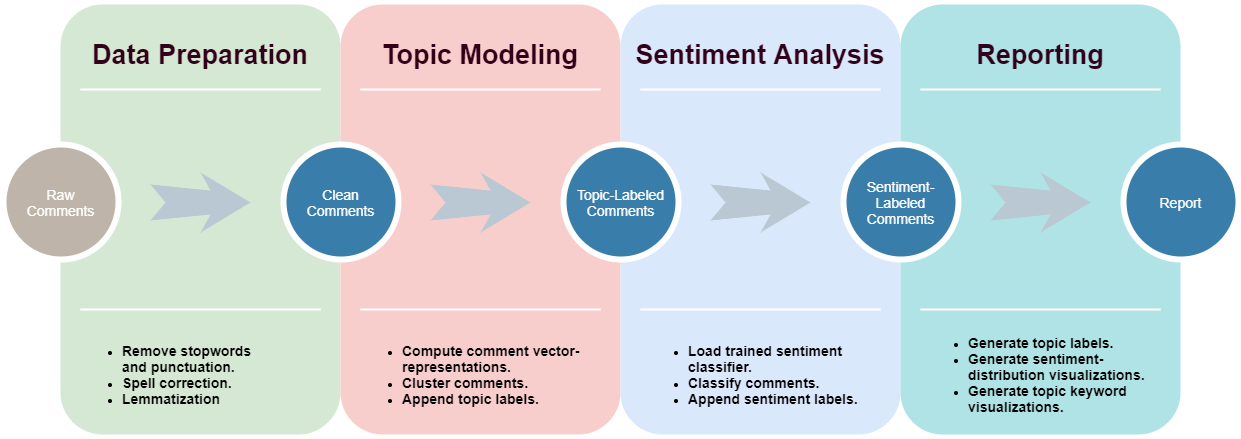
A Note to the Dataset
The dataset we were given to work with by deepsight GmbH contains a total of 17,672 comments. It was produced during an employee survey of a large, international company. The data had previously been anonymized, meaning that all personal information such as the name of the company, individuals' names, and personal data such as phones numbers were removed. Dataset metadata include the prompting questions for each response, such as "Please tell us what needs to be improved" or "Please tell us what is working well" and also the surveyed department, including a small and large department. To provide an impression of the comments we provide below random samples from the dataset:- Team Spirit [company] one stop shop and big brand Good products
- The office environment needs improvement. Cleanliness is an issue in my views. Dirty carpets in hallways & conference rooms. The temperature is never confortable.
- [Name] AS MY DIRECT SUPERVISOR FROM QUESTIONS 14-16, THIS MAN NEEDS A PROMOTION I THINK HE COULD SET AN EXAMPLE FOR EVERYONEON THIS COMPANY
- There should be more performance and achievement visibility per account in order for the individual to gauge customer spend and YOY trends. This will give us a better understanding of their business.
- the mangEMENT
Organization
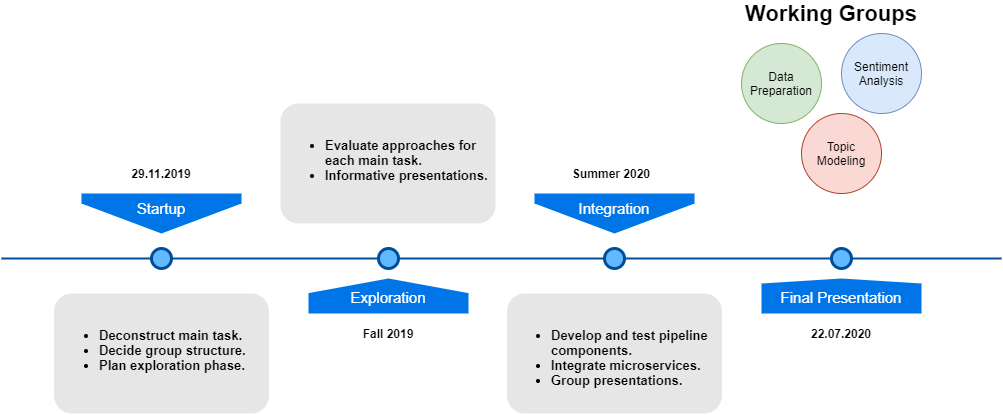
The project was organized into two main phases. The first phase was primarily exploratory, wherein we employed a modified agile methodology to manage the initial testing of available approaches. Further information on the exact methods employed can be found in the presentation 'A Scrum Inspired Approach for Agile Project Management' listed below. This initial exploratory phase was important to identify unsuccessful approaches and refine the end goals of the project before beginning development proper. During the second phase, we implemented, optimized, and integrated the various steps of the aforementioned pipeline. During this phase, the project group was reorganized into three sub-groups each responsible for one of the three main sections of the analysis pipeline represented in this report. Through a series of sub-group-led workshops, the project group coordinated on the continued development and integration of the pipeline components, culminating in the finished deliverable. Further information on sub-group presentations can be found below.
The project timeline and main phases are summarized by the following diagram.
Pitfalls
As mentioned, the exploratory project phase was important to identify approaches which proved unsuccessful for our dataset or otherwise infeasible given computational resource constraints or other limitations. For example, given that the document clustering approach depends on the quality of pretrained word embeddings it was critical to evaluate the available word embedding models before continuing with the approach. We tested several pretrained embeddings computed via several algorithms, including those from Word2Vec and FastText. [2, 3] Further information on the embeddings tested and the final model employed can be found in the Topic Modeling section of the report. Likewise, we first implemented a custom-trained transformer model for sentiment classification, but found this approach to be too computationally costly. Finally, for spell correction we originally implemented a wrapper for the string-matching algorithm developed by Peter Norvig, but found this approach to be too destructive, leading us to develop a proprietary spell correction algorithm based on pretrained word embeddings. Additional information on the outcome of successful methods is found in the Outcome and Reflection section of this report.
Presentations (Click to Download)

This presentation details the scrum-inspired approach to agile project management employed during the exploratory phase. Presented by Jannik Schmitt.

This presentation gives an overview over the technological advances from word embeddings till transformer based technologies like BERT. Presented by Anna Wiedenroth.

This presentation provides an overview of work done in the Data Preparation group during the development phase.

This presentation provides an overview of work done in the Sentiment Analysis group during the development phase.

This presentation provides an overview of work done in the Topic Modeling group during the development phase.

This presentation summarizes the pipeline and preliminary outcomes of the project.
About Us
The project members are all students of Osnabrück University participating in the Cognitive Science masters program. Project members include:- Micaela Barkmann
- Cedric Bitschene
- Subir Das
- Christian Johnson
- Luca Kretz
- Jueun Lee
- Saurabh Mishra
- Jannik Schmitt
- Vedant Shah
- Rebecca Sophia Sylvester
- Maksim Urazov
- Luana Vaduva
- Anna Wiedenroth
References
| [1] | Steinbach, Michael, George Karypis, and Vipin Kumar. (2000). A comparison of document clustering techniques. |
| [2] | Mikolov, Tomas & Corrado, G.s & Chen, Kai & Dean, Jeffrey. (2013). Efficient Estimation of Word Representations in Vector Space. 1-12. |
| [3] | P. Bojanowski, E. Grave, A. Joulin, T. Mikolov. (2016) Enriching Word Vectors with Subword Information. |